声明
声明
声明
- 分析源码为0.7.1版本
- 环境为k8s
- 由于没有C++ 基础,所以源码分析止步于 C++,但也学到很多东西
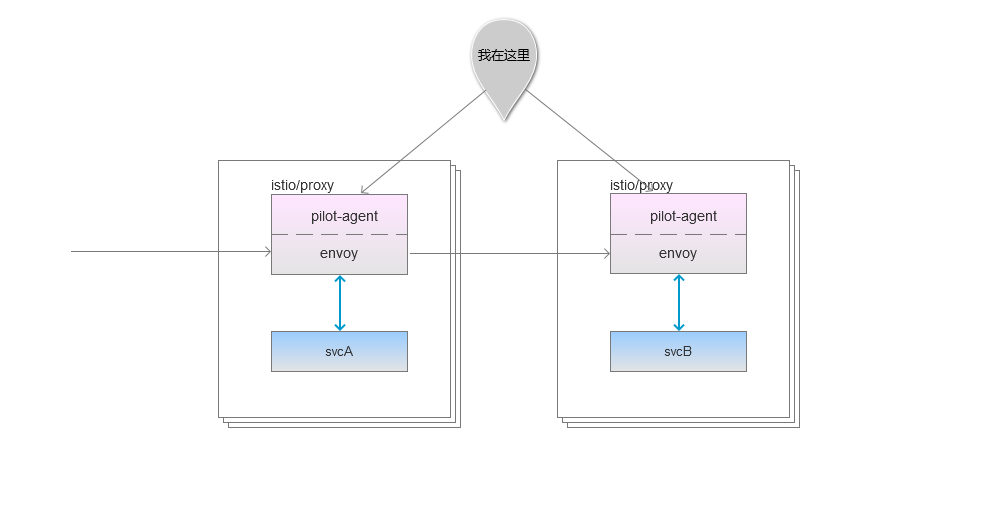
pilot-agent 是什么?
当我们执行
kubectl apply -f <(~istioctl kube-inject -f sleep.yaml)的时候,k8s就会帮我们建立3个容器。
1[root@izwz9cffi0prthtem44cp9z ~]# docker ps |grep sleep
28e0de7294922 istio/proxy
3ccddc800b2a2 registry.cn-shenzhen.aliyuncs.com/jukylin/sleep
4990868aa4a42 registry-vpc.cn-shenzhen.aliyuncs.com/acs/pause-amd64:3.0
在这3个容器中,我们关注
istio/proxy。这个容器运行着2个服务。pilot-agent就是接下来介绍的:如何管理envoy的生命周期。
1[root@izwz9cffi0prthtem44cp9z ~]# docker exec -it 8e0de7294922 ps -ef
2UID PID PPID C STIME TTY TIME CMD
31337 1 0 0 May09 ? 00:00:49 /usr/local/bin/pilot-agent proxy
41337 567 1 1 09:18 ? 00:04:42 /usr/local/bin/envoy -c /etc/ist
为什么要用pilot-agent?
envoy不直接和k8s,Consul,Eureka等这些平台交互,所以需要其他服务与它们对接,管理配置,pilot-agent就是其中一个 【控制面板】。
启动envoy
加载配置
在启动前 pilot-agent 会生成一个配置文件:/etc/istio/proxy/envoy-rev0.json:
1istio.io/istio/pilot/pkg/proxy/envoy/v1/config.go #88
2func BuildConfig(config meshconfig.ProxyConfig, pilotSAN []string) *Config {
3 ......
4 return out
5}
文件的具体内容可以直接查看容器里面的文件
1docker exec -it 8e0de7294922 cat /etc/istio/proxy/envoy-rev0.json
关于配置内容的含义可以看官方的文档
启动参数
一个二进制文件启动总会需要一些参数,envoy也不例外。
1istio.io/istio/pilot/pkg/proxy/envoy/v1/watcher.go #274
2func (proxy envoy) args(fname string, epoch int) []string {
3 ......
4 return startupArgs
5}
envoy启动参数可以通过
docker logs 8e0de7294922查看,下面是从终端截取envoy的参数。了解具体的参数含义官网文档。
1-c /etc/istio/proxy/envoy-rev0.json --restart-epoch 0
2--drain-time-s 45 --parent-shutdown-time-s 60
3--service-cluster sleep
4--service-node sidecar~172.00.00.000~sleep-55b5877479-rwcct.default~default.svc.cluster.local
5--max-obj-name-len 189 -l info --v2-config-only
启动envoy
pilot-agent 使用
exec.Command启动envoy,并且会监听envoy的运行状态(如果envoy非正常退出,status 返回非nil,pilot-agent会有策略把envoy重新启动)。
proxy.config.BinaryPath为envoy二进制文件路径:/usr/local/bin/envoy。
args为上面介绍的envoy启动参数。
1istio.io/istio/pilot/pkg/proxy/envoy/v1/watcher.go #353
2func (proxy envoy) Run(config interface{}, epoch int, abort <-chan error) error {
3 ......
4 /* #nosec */
5 cmd := exec.Command(proxy.config.BinaryPath, args...)
6 cmd.Stdout = os.Stdout
7 cmd.Stderr = os.Stderr
8 if err := cmd.Start(); err != nil {
9 return err
10 }
11 ......
12 done := make(chan error, 1)
13 go func() {
14 done <- cmd.Wait()
15 }()
16
17 select {
18 case err := <-abort:
19 ......
20 case err := <-done:
21 return err
22 }
23}
热更新envoy
在这里我们只讨论pilot-agent如何让envoy热更新,至于如何去触发这步会在后面的文章介绍。
envoy热更新策略
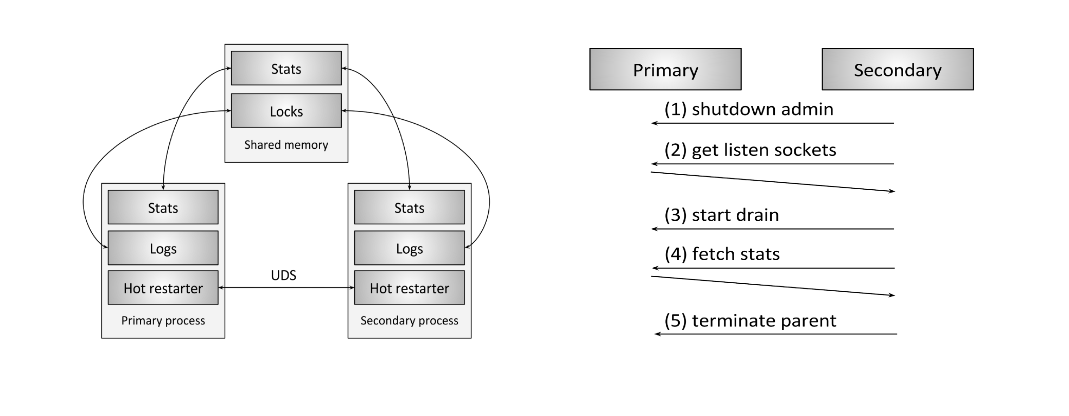
想详细了解envoy的热更新策略可以看官网博客Envoy hot restart。
简单介绍下envoy热更新步骤:
- 启动另外一个envoy2进程(Secondary process)
- envoy2通知envoy1(Primary process)关闭其管理的端口,由envoy2接管
- 通过UDS把envoy1可用的listen sockets拿过来
- envoy2初始化成功,通知envoy1在一段时间内(
drain-time-s)优雅关闭正在工作的请求 - 到了时间(
parent-shutdown-time-s),envoy2通知envoy1自行关闭 - envoy2升级为envoy1
从上面的执行步骤来看,poilt-agent只负责启动另一个envoy进程,其他由envoy自行处理。
什么时候进行热更新?
在poilt-agent启动的时候,会监听
/etc/certs/目录下的文件,如果这个目录下的文件被修改或删除,poilt-agent就会通知envoy进行热更新。至于如何触发对这些文件进行修改和删除会在接下来的文章介绍。
1istio.io/istio/pilot/pkg/proxy/envoy/v1/watcher.go #177
2func watchCerts(ctx context.Context, certsDirs []string, watchFileEventsFn watchFileEventsFn,
3 minDelay time.Duration, updateFunc func()) {
4 fw, err := fsnotify.NewWatcher()
5 if err != nil {
6 log.Warnf("failed to create a watcher for certificate files: %v", err)
7 return
8 }
9 defer func() {
10 if err := fw.Close(); err != nil {
11 log.Warnf("closing watcher encounters an error %v", err)
12 }
13 }()
14
15 // watch all directories
16 for _, d := range certsDirs {
17 if err := fw.Watch(d); err != nil {
18 log.Warnf("watching %s encounters an error %v", d, err)
19 return
20 }
21 }
22 watchFileEventsFn(ctx, fw.Event, minDelay, updateFunc)
23}
热更新启动参数
1-c /etc/istio/proxy/envoy-rev1.json --restart-epoch 1
2--drain-time-s 45 --parent-shutdown-time-s 60
3--service-cluster sleep --service-node
4sidecar~172.00.00.000~sleep-898b65f84-pnsxr.default~default.svc.cluster.local
5--max-obj-name-len 189 -l info
6--v2-config-only
热更新启动参数和第一次启动参数的不同的地方是 -c 和 --restart-epoch,其实-c 只是配置文件名不同,它们的内容是一样的。--restart-epoch 每次进行热更新的时候都会自增1,用于判断是进行热更新还是打开一个存在的envoy(这里的意思应该是第一次打开envoy) 具体看官方描述
1istio.io/istio/pilot/pkg/proxy/agent.go #258
2func (a *agent) reconcile() {
3 ......
4 // discover and increment the latest running epoch
5 epoch := a.latestEpoch() + 1
6 // buffer aborts to prevent blocking on failing proxy
7 abortCh := make(chan error, MaxAborts)
8 a.epochs[epoch] = a.desiredConfig
9 a.abortCh[epoch] = abortCh
10 a.currentConfig = a.desiredConfig
11 go a.waitForExit(a.desiredConfig, epoch, abortCh)
12}
从终端截取触发热更新的日志
12018-04-24T13:59:35.513160Z info watchFileEvents: "/etc/certs//..2018_04_24_13_59_35.824521609": CREATE
22018-04-24T13:59:35.513228Z info watchFileEvents: "/etc/certs//..2018_04_24_13_59_35.824521609": MODIFY|ATTRIB
32018-04-24T13:59:35.513283Z info watchFileEvents: "/etc/certs//..data_tmp": RENAME
42018-04-24T13:59:35.513347Z info watchFileEvents: "/etc/certs//..data": CREATE
52018-04-24T13:59:35.513372Z info watchFileEvents: "/etc/certs//..2018_04_24_04_30_11.964751916": DELETE
抢救envoy
envoy是一个服务,既然是服务都不可能保证100%的可用,如果envoy不幸运宕掉了,那么pilot-agent如何进行抢救,保证envoy高可用?
获取退出状态
在上面提到pilot-agent启动envoy后,会监听envoy的退出状态,发现非正常退出状态,就会抢救envoy。
1func (proxy envoy) Run(config interface{}, epoch int, abort <-chan error) error {
2 ......
3 // Set if the caller is monitoring envoy, for example in tests or if envoy runs in same
4 // container with the app.
5 if proxy.errChan != nil {
6 // Caller passed a channel, will wait itself for termination
7 go func() {
8 proxy.errChan <- cmd.Wait()
9 }()
10 return nil
11 }
12
13 done := make(chan error, 1)
14 go func() {
15 done <- cmd.Wait()
16 }()
17 ......
18}
抢救envoy
使用 kill -9 可以模拟envoy非正常退出状态。当出现非正常退出,pilot-agent的抢救机制会被触发。如果第一次抢救成功,那当然是好,如果失败了,pilot-agent会继续抢救,最多抢救10次,每次间隔时间为 2 n * 100 * time.Millisecond。超过10次都没有救活,pilit-agent就会放弃抢救,宣布死亡,并且退出istio/proxy,让k8s重新启动一个新容器。
1istio.io/istio/pilot/pkg/proxy/agent.go #164
2func (a *agent) Run(ctx context.Context) {
3 ......
4 for {
5 ......
6 select {
7 ......
8 case status := <-a.statusCh:
9 ......
10 if status.err == errAbort {
11 //pilot-agent通知退出 或 envoy非正常退出
12 log.Infof("Epoch %d aborted", status.epoch)
13 } else if status.err != nil {
14 //envoy非正常退出
15 log.Warnf("Epoch %d terminated with an error: %v", status.epoch, status.err)
16 ......
17 a.abortAll()
18 } else {
19 //正常退出
20 log.Infof("Epoch %d exited normally", status.epoch)
21 }
22 ......
23 if status.err != nil {
24 // skip retrying twice by checking retry restart delay
25 if a.retry.restart == nil {
26 if a.retry.budget > 0 {
27 delayDuration := a.retry.InitialInterval * (1 << uint(a.retry.MaxRetries-a.retry.budget))
28 restart := time.Now().Add(delayDuration)
29 a.retry.restart = &restart
30 a.retry.budget = a.retry.budget - 1
31 log.Infof("Epoch %d: set retry delay to %v, budget to %d", status.epoch, delayDuration, a.retry.budget)
32 } else {
33 //宣布死亡,退出istio/proxy
34 log.Error("Permanent error: budget exhausted trying to fulfill the desired configuration")
35 a.proxy.Panic(a.desiredConfig)
36 return
37 }
38 } else {
39 log.Debugf("Epoch %d: restart already scheduled", status.epoch)
40 }
41 }
42 case <-time.After(delay):
43 ......
44 case _, more := <-ctx.Done():
45 ......
46 }
47 }
48}
1istio.io/istio/pilot/pkg/proxy/agent.go #72
2var (
3 errAbort = errors.New("epoch aborted")
4 // DefaultRetry configuration for proxies
5 DefaultRetry = Retry{
6 MaxRetries: 10,
7 InitialInterval: 200 * time.Millisecond,
8 }
9)
抢救日志
1Epoch 6: set retry delay to 200ms, budget to 9
2Epoch 6: set retry delay to 400ms, budget to 8
3Epoch 6: set retry delay to 800ms, budget to 7
优雅关闭envoy
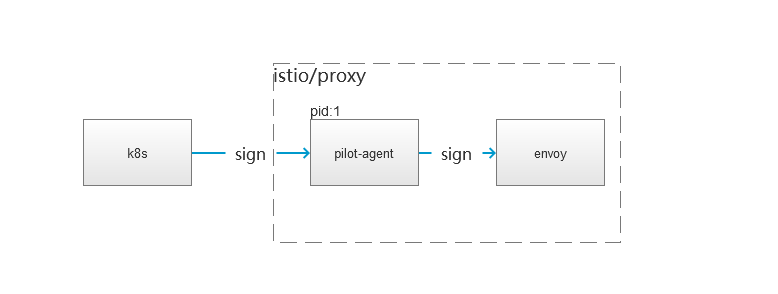
服务下线或升级我们都希望它们能很平缓的进行,让用户无感知 ,避免打扰用户。这就要服务收到退出通知后,处理完正在执行的任务才关闭,而不是直接关闭。envoy是否支持优雅关闭?这需要k8s,pilot-agent也支持这种玩法。因为这存在一种关联关系k8s管理pilot-agent,pilot-agent管理envoy。
k8s让服务优雅退出
网上有篇博客总结了k8s优雅关闭pods,我这边简单介绍下优雅关闭流程:
- k8s 发送 SIGTERM 信号到pods下所有服务的1号进程
- 服务接收到信号后,优雅关闭任务,并退出
- 过了一段时间(default 30s),如果服务没有退出,k8s会发送 SIGKILL 信号,让容器强制退出。
pilot-agent 让envoy优雅退出
- pilot-agent接收k8s信号
pilot-agent会接收syscall.SIGINT, syscall.SIGTERM,这2个信号都可以达到优雅关闭envoy的效果。
1istio.io/istio/pkg/cmd/cmd.go #29
2func WaitSignal(stop chan struct{}) {
3 sigs := make(chan os.Signal, 1)
4 signal.Notify(sigs, syscall.SIGINT, syscall.SIGTERM)
5 <-sigs
6 close(stop)
7 _ = log.Sync()
8}
- 通知子服务关闭envoy
在golang有一个上下文管理包
context,这个包通过广播的方式通知各子服务执行关闭操作。
1istio.io/istio/pilot/cmd/pilot-agent/main.go #242
2ctx, cancel := context.WithCancel(context.Background())
3go watcher.Run(ctx)
4stop := make(chan struct{})
5cmd.WaitSignal(stop)
6<-stop
7//通知子服务
8cancel()
9
10istio.io/istio/pilot/pkg/proxy/agent.go
11func (a *agent) Run(ctx context.Context) {
12 ......
13 for {
14 ......
15 select {
16 ......
17 //接收到主服务信息通知envoy退出
18 case _, more := <-ctx.Done():
19 if !more {
20 a.terminate()
21 return
22 }
23 }
24 }
25}
26
27istio.io/istio/pilot/pkg/proxy/envoy/v1/watcher.go #297
28func (proxy envoy) Run(config interface{}, epoch int, abort <-chan error) error {
29 ......
30 select {
31 case err := <-abort:
32 log.Warnf("Aborting epoch %d", epoch)
33 //发送 KILL信号给envoy
34 if errKill := cmd.Process.Kill(); errKill != nil {
35 log.Warnf("killing epoch %d caused an error %v", epoch, errKill)
36 }
37 return err
38 ......
39 }
40}
上面展示了pilot-agent从k8s接收信号到通知envoy关闭的过程,这个过程说明了poilt-agent也是支持优雅关闭。但最终envoy并不能进行优雅关闭,这和pilot-agent发送KILL信号没关系,这是因为envoy本身就不支持。
envoy优雅关闭
- 遗憾通知
来到这里很遗憾通知你envoy自己不能进行优雅关闭,envoy会接收SIGTERM,SIGHUP,SIGCHLD,SIGUSR1这4个信号,但是这4个都与优雅无关,这4个信号的作用可看官方文档。当然官方也注意到这个问题,可以到github了解一下2920 3307。
- 替代方案
其实使用优雅关闭想达到的目的是:让服务平滑升级,减少对用户的影响。所以我们可以用金丝雀部署来实现,并非一定要envoy实现。大致的流程:
- 定义服务的旧版本(v1),新版本(v2)
- 发布新版本
- 将流量按照梯度的方式,慢慢迁移到v2
- 迁移完成,运行一段时间,没问题就关闭v1
- golang 优雅退出HTTP服务
借此机会了解下golang的优雅关闭,golang在1.8版本的时候就支持这个特性
1net/http/server.go #2487
2func (srv *Server) Shutdown(ctx context.Context) error {
3 atomic.AddInt32(&srv.inShutdown, 1)
4 defer atomic.AddInt32(&srv.inShutdown, -1)
5
6 srv.mu.Lock()
7 // 把监听者关掉
8 lnerr := srv.closeListenersLocked()
9 srv.closeDoneChanLocked()
10 //执行开发定义的函数如果有
11 for _, f := range srv.onShutdown {
12 go f()
13 }
14 srv.mu.Unlock()
15
16 //定时查询是否有未关闭的链接
17 ticker := time.NewTicker(shutdownPollInterval)
18 defer ticker.Stop()
19 for {
20 if srv.closeIdleConns() {
21 return lnerr
22 }
23 select {
24 case <-ctx.Done():
25 return ctx.Err()
26 case <-ticker.C:
27 }
28 }
29}
其实golang的关闭机制和envoy在github上讨论优雅关闭机制很相似:
golang机制
- 关闭监听者(
ln, err := net.Listen("tcp", addr),向ln赋nil) - 定时查询是否有未关闭的链接
- 所有链接都是退出,服务退出
envoy机制:
- ingress listeners stop accepting new connections (clients see TCP connection refused) but continues to service existing connections. egress listeners are completely unaffected
- configurable delay to allow workload to finish servicing existing connections
- envoy (and workload) both terminate